プログラミング必須英単語を効率よく暗記する方法
こんにちは。レーザービームタイピストのまるりんです。
プログラミングを学んでいると英単語がよく出てきます。英単語を理解していると学習もスムーズに進むのではないでしょうか。 そこで今回はタイピングゲームを通じてプログラミングに必要な英単語を効率的に暗記してみましょう。
このゲームはプレイするだけでなく、ユーザが単語を登録できます。 シェルを使って登録用CSVファイルを作成する過程も説明します。
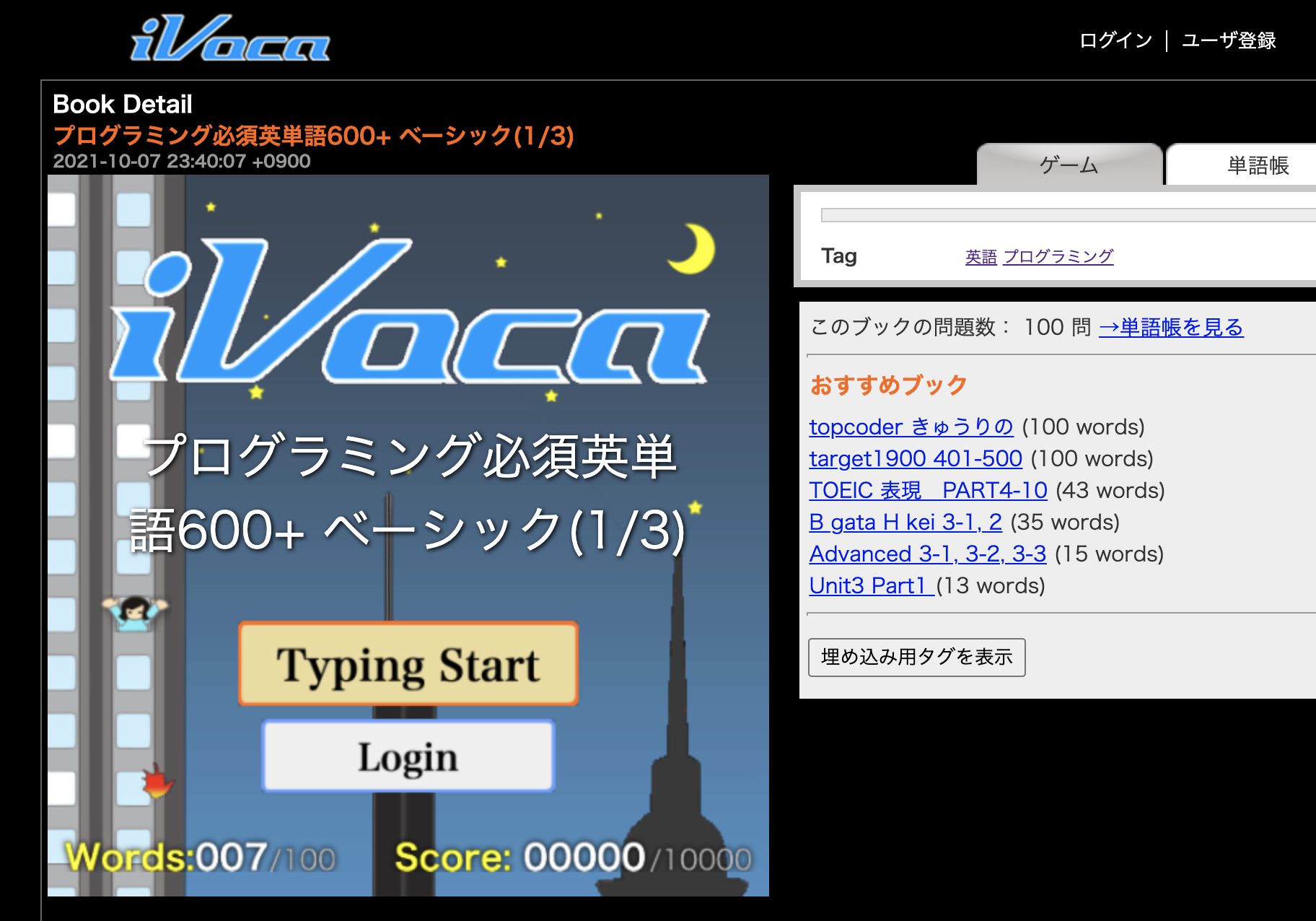
以下がゲームのURLです。
プログラミング必須英単語600+ 前提英単語
プログラミング必須英単語600+ ベーシック(1/3)
プログラミング必須英単語600+ ベーシック(2/3)
プログラミング必須英単語600+ ベーシック(3/3)
プログラミング必須英単語600+ アドバンスト(1/3)
プログラミング必須英単語600+ アドバンスト(2/3)
プログラミング必須英単語600+ アドバンスト(3/3)
タイピングゲームサービス
iVocaというタイピングゲームのサービスを使います。 前時代的なデザインですが機能としては十分です。
https://ivoca.31tools.com/home
単語データ
単語データは『プログラミング必須英単語600+』を用います。
https://progeigo.org/wp-content/uploads/2020/04/essential-programming-words-600-plus_v2020-04.pdf
単語データに含まれている以下を登録します。
- 前提英単語(100語。ベーシック以前に覚えておくべき入門的な英単語)
- ベーシック(300語。基本的な英単語または頻出する英単語)
- アドバンスト(300語。やや高度な英単語またはたまに目にする英単語)
登録用CSVファイルの作成
登録用CSVファイル作成の流れです。
- コピペでPDFの単語データをテキストファイルに転記
- シェルを駆使してテキストファイルの整形、CSV化
- CSVファイルをiVocaに登録
コピペでPDFの単語データをテキストファイルに転記
PDFからベーシックの300語をコピーしてテキストファイルに貼り付けます。ここに特に芸はありません。
シェルを駆使してテキストファイルの整形、CSV化
普通にコピペしたところ、行が崩れていました。
以下のコマンドで行を整えます。コマンドで修正できない部分は手で直します。 処理の概要はファイルに存在する改行をすべて削除し、次に単語単位で改行し、元ファイルに内容を書き出しています。
$ perl -pe 's/\n//g' basic300.txt | sed -E 's/([a-z-]+)/\n\1/g' | sed 's/ $//g' | sponge basic300.txt
$ # 若干の手修正
$ sort basic300.txt | uniq | sponge basic300.txt # 念のためにuniq
$ wc -l basic300.txt # 300行(語)になったことを確認
300 basic300.txt
$ head -3 basic300.txt
accept【動詞】受諾する、受け入れる
access【動詞∕名詞】アクセスする、利用する、入手する∕アクセス
account【名詞】アカウント、口座品詞が冗長なので動詞→動などに省略します。 まず品詞のパターンを取り出すために後方参照で品詞部分を抜き出します。
$ sed -E 's/(.*)(【.*】)(.*)/\2/' basic300.txt | sort | uniq
【副詞】
【動詞】
【名詞】
【代名詞】
【前置詞】
【形容詞】
【動詞∕名詞】
【名詞∕動詞】
【動詞∕形容詞】
【名詞∕形容詞】
【形容詞∕動詞】
【形容詞∕名詞】上記のパターンがあるとわかったので地道に置換します。
$ sed -i '' 's/【副詞】/【副】/' basic300.txt
$ sed -i '' 's/【動詞】/【動】/' basic300.txt
$ sed -i '' 's/【名詞】/【名】/' basic300.txt
$ sed -i '' 's/【代名詞/【代】/' basic300.txt
$ sed -i '' 's/【前置詞】/【前】/' basic300.txt
$ sed -i '' 's/【形容詞】/【形】/' basic300.txt
$ sed -i '' 's/【動詞∕名詞】/【動∕名】/' basic300.txt
$ sed -i '' 's/【名詞∕動詞】/【名∕動】/' basic300.txt
$ sed -i '' 's/【動詞∕形容詞】/【動∕形】/' basic300.txt
$ sed -i '' 's/【名詞∕形容詞】/【名∕形】/' basic300.txt
$ sed -i '' 's/【形容詞∕動詞】/【形∕動】/' basic300.txt
$ sed -i '' 's/【形容詞∕名詞】/【形∕名】/' basic300.txtCSV化し、意味が重複している場合に連番を振ります。
$ awk -F'【' '{print $1",【"$2}' basic300.txt > basic300.csv
$ awk -F',' '{words[$2]++}{printf $1","$2}{if(words[$2]>1)printf "%d",words[$2]}{printf "\n"}' basic300.csv | sponge basic300.csviVocaには100単語単位で登録します。ランダムに並び替えを行い、100単語ずつ分割します。
$ sort -R basic300.csv > randomized_basic300.csv
$ split -l 100 randomized_basic300.csv
$ ls xa*
xaa xab xac # 100単語ずつ分割されたCSVこれで登録用CSVファイルが完成しました。
CSVファイルをiVocaに登録
iVocaのアカウントを作成し、CSVファイルを登録します。
$ pbcopy < xaa # クリップボードの内容をiVocaに登録
$ pbcopy < xab
$ pbcopy < xac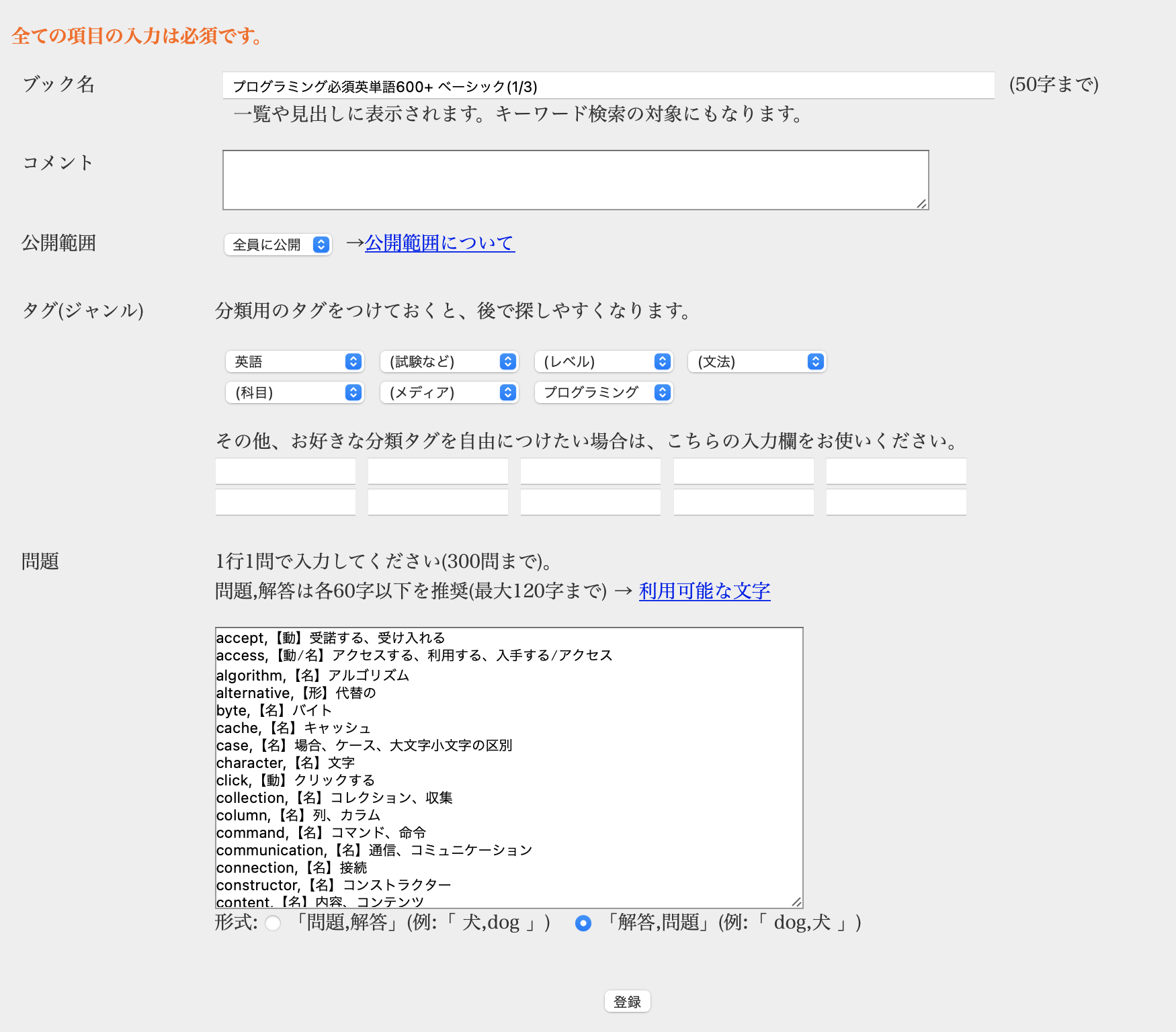
以上の流れでタイピングゲームの完成です。